

Where did all the IOPS go…In the rapidly changing world of data storage and management, the traditional challenges of achieving high I/O performance have transformed. With the advent of new data paradigms, unstructured data, and the rise of NoSQL databases, organizations are reevaluating their approach to schema design and data organization. As a result, the I/O landscape has shifted from a focus on high IOPS to a demand for scalable throughput solutions.
In the past, databases heavily relied on a rigid structured approach, where schema designs were carefully crafted to efficiently organize and retrieve data. This required deep understanding of the raw data and often involved pre-processing steps, such as Extract Transform Load (ETL) operations, to sort and load data into tables. The goal was to achieve high IOPS and low latency for efficient data access.
However, with the emergence of flash storage, the limitations of backend spindles were overcome, and storage systems became capable of handling dynamic workloads. Despite these advancements, the high cost associated with achieving extremely high IOPS, coupled with the exponential growth of data, rendered it an impractical solution.
A significant shift occurred as organizations embraced alternative database designs, such as Schema on read, that prioritize flexibility and on-the-fly schema creation. This approach eliminates the need for extensive pre-processing and deep understanding of the data elements. Raw data is loaded and sorted dynamically, revolutionizing the I/O profile.
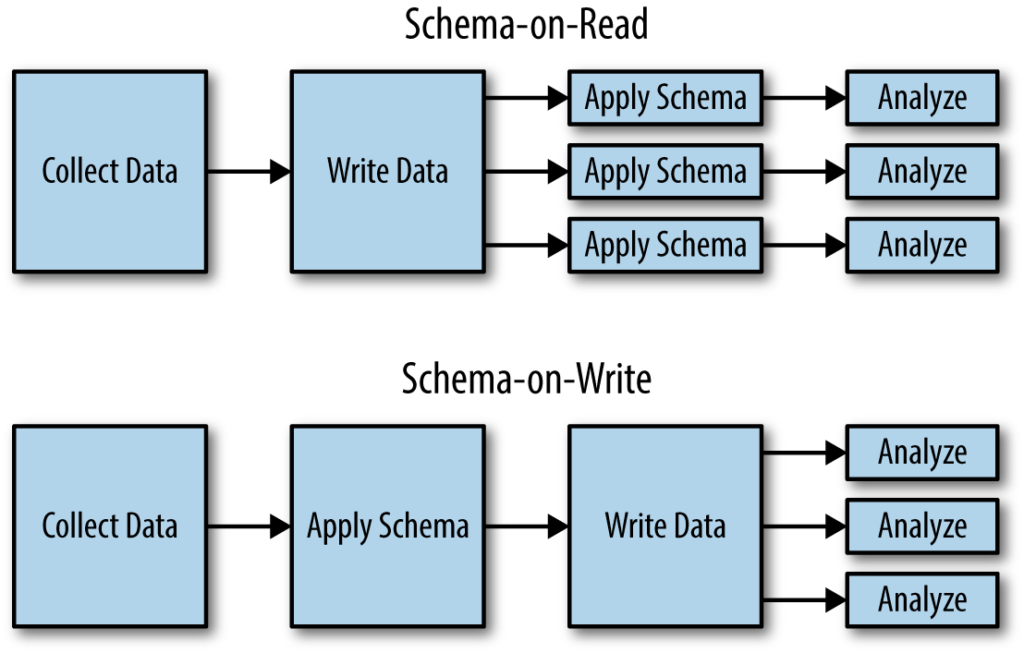
With the new data paradigms and the growing importance of managing diverse data types, the focus has shifted from high IOPS to scalable throughput. Rather than obsessing over individual I/O operations, organizations now seek storage solutions that offer scalability, cost-effectiveness, geographical distribution, data resilience, simplified management, and compatibility with cloud-native applications.
Object storage, with its inherent scalability, flexible metadata capabilities, and ability to seamlessly integrate with cloud services, has emerged as a fitting solution for the evolving I/O landscape. Its high throughput capabilities, combined with its ability to handle unstructured data, make it well-suited for modern data requirements.
So as I think about this change to the beat of a cheesy 80’s song from Bonnie Tyler and we delve into the transformation of the I/O landscape, exploring the reasons behind the shift from high IOPS to scalable throughput. We need to examine how changes in database design and data organization have played a role in redefining storage requirements. By understanding these shifts, we can embrace the benefits of object storage and leverage its unique features to tackle the challenges presented by the ever-growing data landscape.
As we navigate the evolving world of data storage and explore the new paradigms that have reshaped the I/O landscape, paving the way for scalable throughput and efficient data management we have to remember that a Hero is not the only way to win a fight.
